

Hello,大家好呀,我是你们亲爱的 w3cschool 小编,今天给大家分享一份 Python 爬虫入门小案例----语音播报天气预报。
此案例实现的功能为:利用爬虫,爬取某一地区的天气信息,并打印出进行语音播报。
一、前期准备
此案例中要用到的库有:requests、lxml、pyttsx3,可通过 cmd 命令进去命令提示符界面,通过如下命令安装:
pip install requests
pip install lxml
pip install pyttsx3
requests 比 urllib 更加方便,可以节约我们大量的工作。(用了 requests 之后,你基本都不愿意用 urllib 了)一句话,requests 是 Python 实现的最简单易用的 HTTP 库,建议爬虫使用 requests 库。
lxml 是 Python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPath 解析方式,而且解析效率非常高。
pyttsx3 是一个款将文本转为语音的 Python 包,不同于其他 Python 包,pyttsx3 真的可以文本转语音。基本用法如下:
import pyttsx3
test = pyttsx3.init()
test.say('hello w3cschool!')
# 关键一句,若无,语音不会播放
test.runAndWait()
如果你是 linux 系统,pyttsx3 文本转语音不奏效。那么你可能还需要安装 espeak、ffmpeg 和 libespeak1。安装命令如下:
sudo apt update && sudo apt install espeak ffmpeg libespeak1
爬虫是爬取网页的相关内容,了解 HTML 能够帮助你更好的理解网页的结构、内容等。
TCP / IP 协议,HTTP 协议这些知识最好要了解一下,懂得基本含义,这样能够让你了解在网络请求和网络传输上的基本原理。
二、详细步骤
1、get 请求目标网址
我们首先导入 requests 库,然后就用它来获取目标的网页,我们请求的是天气网站中的厦门天气。
import requests
# 向目标url地址发送请求,返回一个response对象
resp = requests.get('https://www.tianqi.com/xaimen/')
# .text是response对象的网页html
print(resp.text)
当然仅凭这三行代码,很大的可能是爬取不到网页的,显示 403,这是什么意思呢?
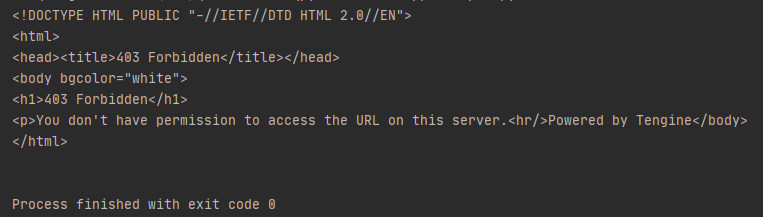
403 错误是一种常见的网络错误类型,表示资源不可用,服务器知道客户的请求,但拒绝处理它。
这是因为我们写的爬虫如果不添加请求头进行访问的话,脚本会自行发送一个 Python 爬取的请求,而大部分的网站都会设施反爬虫机制,不允许网站内容被爬虫爬取。
那么,这就无解了吗?那肯定是不可能的,俗话说得好,上有政策,下有对策,我们想让目标服务器相应,那么我们就对我们得爬虫进行一下伪装即可。在我们这次的小案例中我们添加常用的 User-Agent 字段进行伪装即可。
所以,改一下我们之前得代码,将爬虫伪装成浏览器请求,如下:
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
# 向目标url地址发送请求,返回一个response对象
resp = requests.get('https://www.tianqi.com/xaimen/',headers=headers)
# .text是response对象的网页html
print(resp.text)
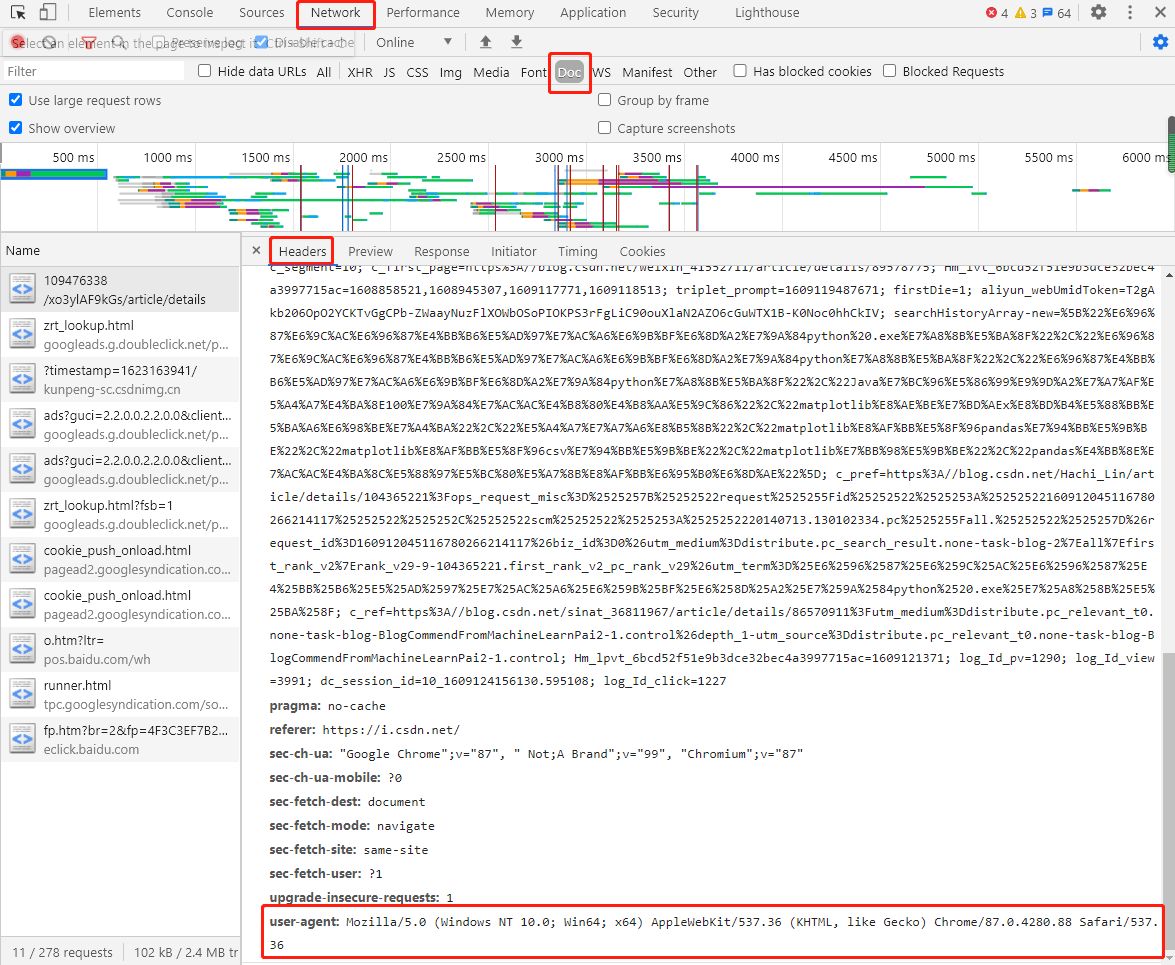
有小伙伴就要问了:User-Agent 字段怎么来的呢?在这里我们以 Chrome 浏览器为例子,先随便打开一个网页,按键盘的 F12 或在空白处点击鼠标右键选择“检查”;然后刷新网页,点击“Network”再点击“Doc”,点击 Headers,在信息栏查看Request Headers 的 User-Agent 字段,直接复制,黏贴到编译器就可以用啦,注意要以字典形式添加呀。
2、lxml.etree 解析网页
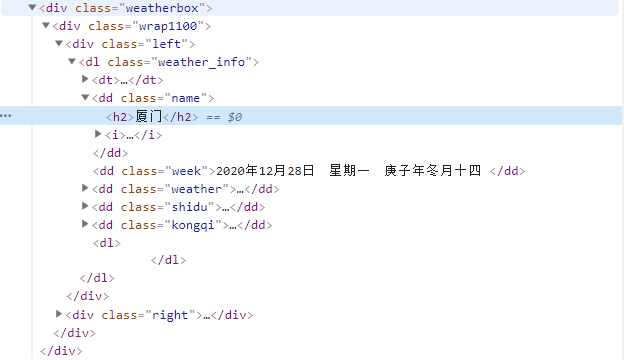
我们从网页爬取到得数据杂乱,其中也只有一部分是我们真正想要得到得数据,例如在本案例中我们只需网页中厦门市的天气详细信息,如图所示:
那么我们如如何提取呢?这时候就要用到 lxml.etree 啦。
观察网页结构可以发现我们所需要的天气信息都在“dl class='weather_info'”这一自定义列表下,于是乎我们只需在之前的代码后添加如下代码便能解析出该信息了:
html = etree.HTML(html)
html_data = html.xpath("//d1[@class='weather_info']//text()")
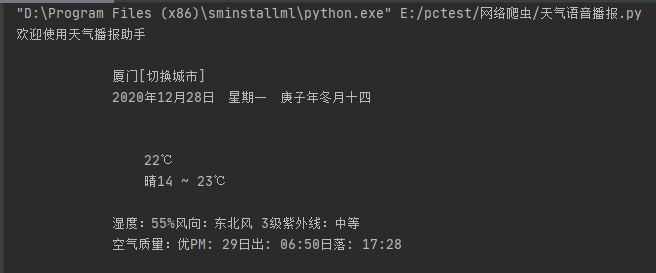
我们尝试一下打印其中信息,得到信息如图所示:

不难发现,得到的信息和我们想要的信息不是很一致,网页中的空格及换行符也一并让我们提取了出来,生成的对象也是列表类型。
所以呢,我们接下来还需做如下处理:
txt = "欢迎使用天气播报助手"
for data in html_data:
txt += data
再次打印不难发现我们所需要的信息都已经有了,看上去也是很 nice,不过美中不足的是 [切换城市] 还在,我们呢也不想要它。
那么怎么办呢,咱用字符串方法替换掉它即可。
txt = txt.replace('[切换城市]','')
三、pyttsx3 播报天气信息
到这一步,我们想要的数据都已被我们爬取下来并处理好保存在 txt 变量里啦,现在就让他读出来,到了 pyttsx3 这个库上场的时候了,代码如下:
test = pyttsx3.init()
test.say(txt)
test.runAndWait()
至此,我们的小案例就做完啦,推荐好课:Python 静态爬虫、Python Scrapy网络爬虫。
一步步的摸索,到功能的实现,在其中得到的乐趣及成就感,相信小伙伴们是很开心的。
最后:完整源码奉上:
import requests
import pyttsx3
from lxml import etree
url = 'https://www.tianqi.com/xiamen/'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
resp = requests.get(url=url, headers=headers) # 向目标url地址发送请求,返回一个response对象
html = resp.text # .text是response对象的网页html
html = etree.HTML(html)
html_data = html.xpath("//dl[@class='weather_info']//text()")
txt = "欢迎使用天气播报助手"
for data in html_data:
txt += data
print(txt)
txt = txt.replace('[切换城市]','')
txt += '\n播报完毕!谢谢!'
print(txt)
test = pyttsx3.init()
test.say(txt)
test.runAndWait()



