

一、scrapy爬虫框架介绍
在编写爬虫的时候,如果我们使用 requests、aiohttp 等库,需要从头至尾把爬虫完整地实现一遍,比如说异常处理、爬取调度等,如果写的多了,的确会比较麻烦。利用现有的爬虫框架,可以提高编写爬虫的效率,而说到 Python 的爬虫框架,Scrapy 当之无愧是最流行最强大的爬虫框架了。
scrapy介绍
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。我们只需要定制开发几个模块就可以轻松实现一个爬虫。
scrapy爬虫框架的架构如下图所示:
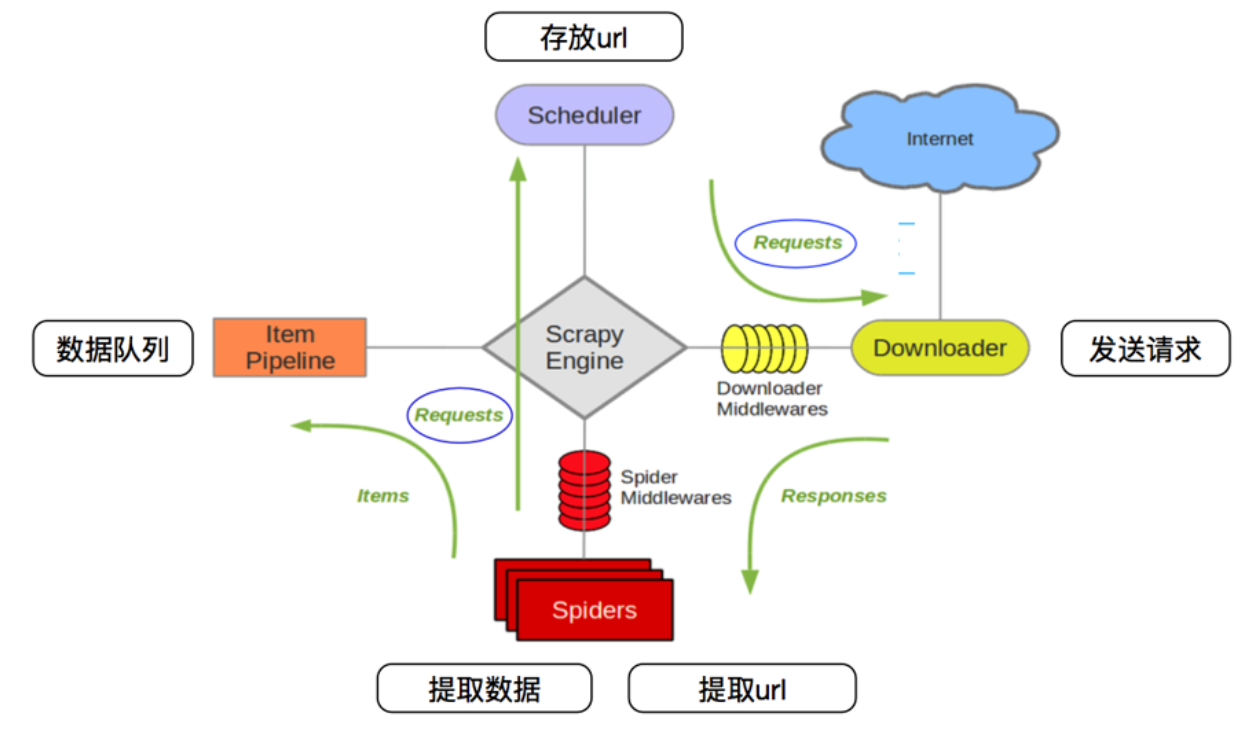
它有如下几个部分:
- Scrapy Engine(引擎):用来处理整个系统的数据流处理、触发事务,是整个框架的核心。
- Item(项目):定义了爬取结果的数据结构,爬取的数据会被赋值成该对象。
- Scheduler(调度器):用来接受引擎发过来的请求并加入队列中,并在引擎再次请求的时候提供给引擎。
- Item Pipeline(项目管道):负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
- Downloader(下载器):用于下载网页内容,并将网页内容返回给Spiders。
- Spiders(蜘蛛):其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提取结果和新的请求。
- Downloader Middlewares(下载器中间件):位于引擎和下载器之间的钩子框架,主要是处理引擎与下载器之间的请求及响应。
- Spider Middlewares(Spiders中间件):位于引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛输入的响应和输出的结果及新的请求。
Scrapy数据流机制
scrapy 中的数据流由引擎控制,其过程如下:
- Engine 首先打开一个网站,找到处理该网站的 Spider 并向该 Spider 请求第一个要爬取的 URL。
- Engine 从 Spider 中获取到第一个要爬取的 URL 并通过 Scheduler 以 Request 的形式调度。
- Engine 向 Scheduler 请求下一个要爬取的 URL。
- Scheduler 返回下一个要爬取的 URL 给 Engine,Engine 将 URL 通过 Downloader Middlewares 转发给 Downloader 下载。
- 一旦页面下载完毕, Downloader 生成一个该页面的 Response,并将其通过 Downloader Middlewares 发送给 Engine。
- Engine 从下载器中接收到 Response 并通过 Spider Middlewares 发送给 Spider 处理。
- Spider 处理 Response 并返回爬取到的 Item 及新的 Request 给 Engine。
- Engine 将 Spider 返回的 Item 给 Item Pipeline,将新的 Request 给 Scheduler。
- 重复第二步到最后一步,直到 Scheduler 中没有更多的 Request,Engine 关闭该网站,爬取结束。
通过多个组件的相互协作、不同组件完成工作的不同、组件很好地支持异步处理,scrapy 最大限度地利用了网络带宽,大大提高了数据爬取和处理的效率。
二、scrapy的安装和创建项目
pip install Scrapy -i http://pypi.douban.com/simple --trusted-host pypi.douban.com安装方法参考官方文档:https://docs.scrapy.org/en/latest/intro/install.html
安装完成之后,如果可以正常使用 scrapy 命令,那就是安装成功了。
Scrapy是框架,已经帮我们预先配置好了很多可用的组件和编写爬虫时所用的脚手架,也就是预生成一个项目框架,我们可以基于这个框架来快速编写爬虫。
Scrapy框架是通过命令行来创建项目的,创建项目的命令如下:
scrapy startproject practice命令执行后,在当前运行目录下便会出现一个文件夹,叫作practice,这就是一个Scrapy 项目框架,我们可以基于这个项目框架来编写爬虫。
project/
__pycache__
spiders/
__pycache__
__init__.py
spider1.py
spider2.py
...
__init__.py
items.py
middlewares.py
pipelines.py
settings.py
scrapy.cfg各个文件的功能描述如下:
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
- spiders:其内包含一个个 Spider 的实现,每个 Spider 都有一个文件。
三、scrapy的基本使用
实例1:爬取 Quotes
- 创建一个 Scrapy 项目。
- 创建一个 Spider 来抓取站点和处理数据。
- 通过命令行运行,将抓取的内容导出。
目标URL:http://quotes.toscrape.com/
创建项目
创建一个 scrapy 项目,项目文件可以直接用 scrapy 命令生成,命令如下所示:
scrapy startproject practice 创建Spider
Spider是自己定义的类,scrapy用它从网页里抓取内容,并解析抓取的结果。这个类必须继承 Scrapy 提供的Spider类scrapy.Spider,还要定义Spider的名称和起始请求,以及怎样处理爬取后的结果的方法。
使用命令行创建一个Spider,命令如下:
cd practice
scrapy genspider quotes quotes.toscrape.com切换路径到刚才创建的practice文件夹,然后执行genspider命令。第一个参数是Spider的名称,第二个参数是网站域名。执行完毕之后,spiders 文件夹中多了一个quotes.py,它就是刚刚创建的Spider,内容如下:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass可以看到quotes.py里有三个属性——name、allowed_domains 和 start_urls,还有一个方法 parse。
- name:它是每个项目唯一的名字,用来区分不同的 Spider。
- allowed_domains:它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
- start_urls:它包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的。
- parse:它是 Spider 的一个方法。默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
创建 Item
Item 是保存爬取数据的容器,它的使用方法和字典类似。不过,相比字典,Item 多了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建 Item 需要继承 scrapy.Item 类,并且定义类型为 scrapy.Field 的字段。观察目标网站,我们可以获取到的内容有 text、author、tags。
定义Item,此时进入items.py修改如下:
import scrapy
class QuoteItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()定义了三个字段,并将类的名称修改为QuoteItem,接下来爬取时会使用到这个 Item。
解析 Response
parse 方法的参数 response 是 start_urls 里面的链接爬取后的结果。所以在 parse 方法中,我们可以直接对 response 变量包含的内容进行解析,比如浏览请求结果的网页源代码,或者进一步分析源代码内容,或者找出结果中的链接而得到下一个请求。
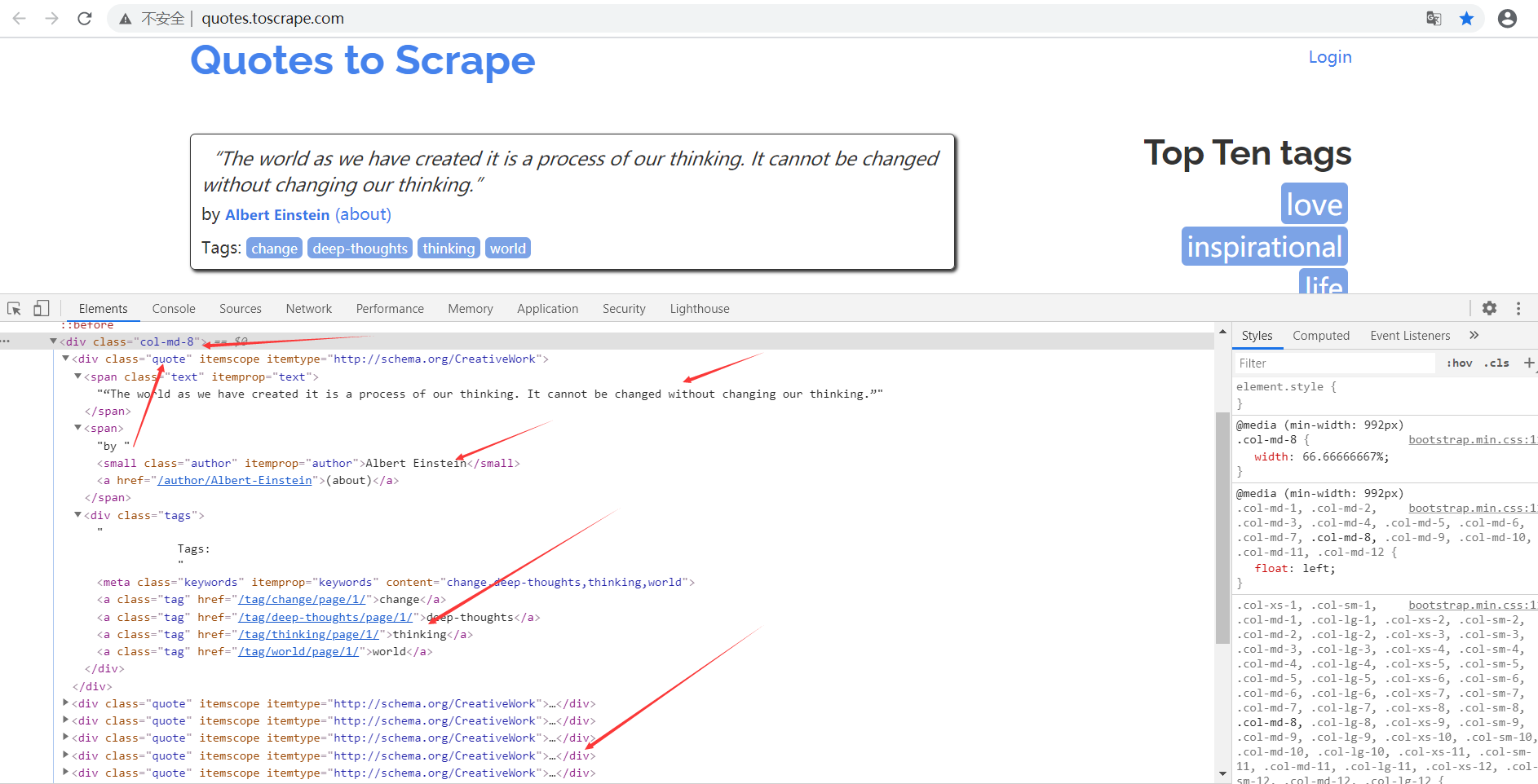
可以看到网页中既有想要提取的数据,又有下一页的链接,这两部分内容都可以进行处理。
首先看看网页结构,如图所示。每一页都有多个 class 为 quote 的区块,每个区块内都包含 text、author、tags。那么我们先找出所有的 quote,然后提取每一个 quote 中的内容。
提取数据的方式可以是 CSS 选择器 或 XPath 选择器
使用 Item
上文定义了 Item,接下来就要使用它了。Item 可以理解为一个字典,不过在声明的时候需要实例化。然后依次用刚才解析的结果赋值 Item 的每一个字段,最后将 Item 返回即可。
import scrapy
from practice.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response, **kwargs):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item后续 Request
上面的操作实现了从初始页面抓取内容。实现翻页爬取,这就需要从当前页面中找到信息来生成下一个请求,然后在下一个请求的页面里找到信息再构造下一个请求。这样循环往复迭代,从而实现整站的爬取。
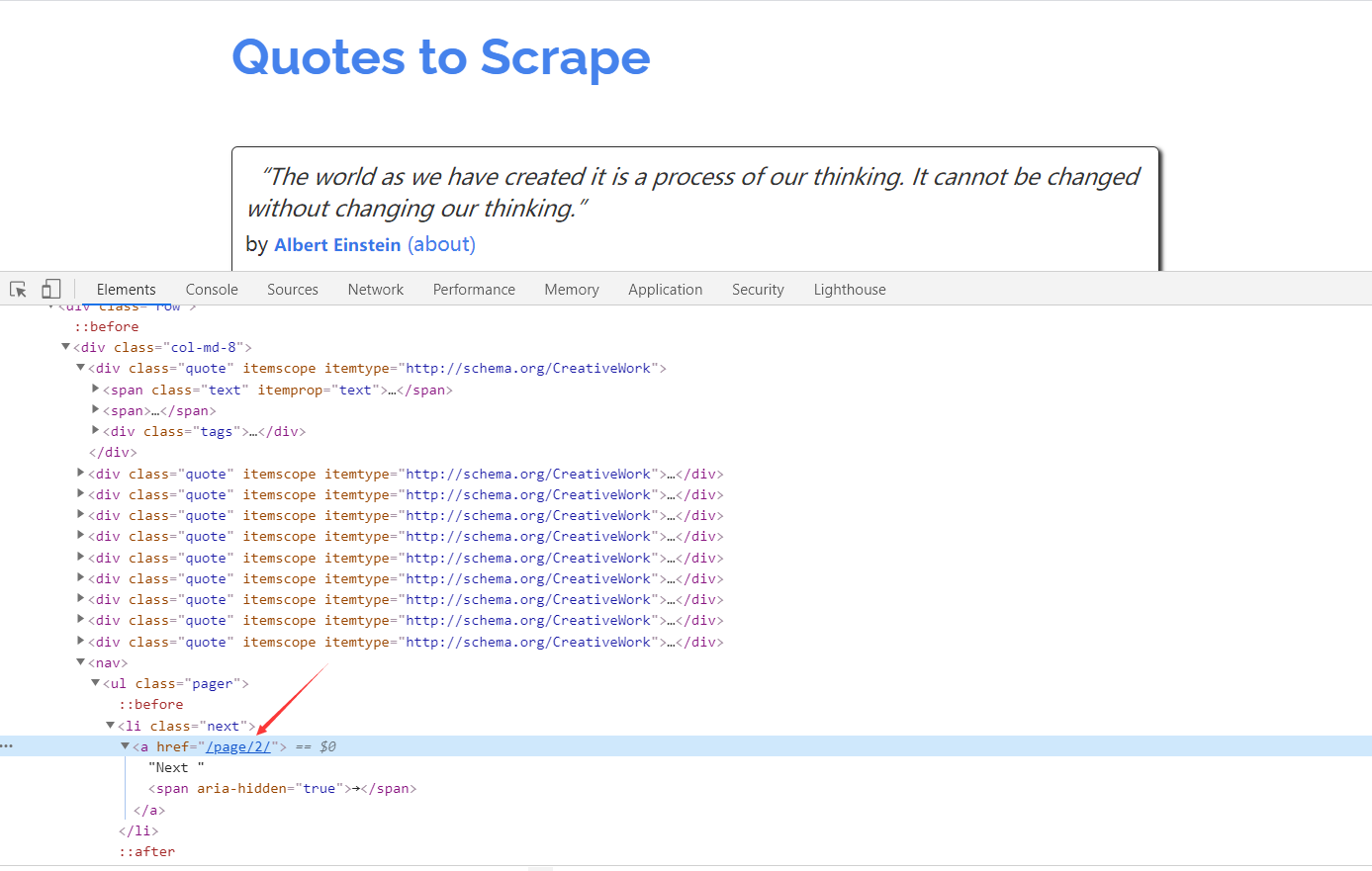
查看网页源代码,可以发现下一页的链接是 /page/2/,但实际上全链接为:http://quotes.toscrape.com/page/2/ ,通过这个链接就可以构造下一个请求。
构造请求时需要用到 scrapy.Request。这里我们传递两个参数—— url 和 callback,这两个参数的说明如下:
- url:它是请求链接
- callback:它是回调函数。当指定了该回调函数的请求完成之后,获取到响应,引擎会将该响应作为参数传递给这个回调函数。回调函数进行解析或生成下一个请求,回调函数如上文的
parse()所示。
由于 parse 就是解析 text、author、tags 的方法,而下一页的结构和刚才已经解析的页面结构是一样的,所以我们可以再次使用 parse 方法来做页面解析。
"""
@Author :叶庭云
@Date :2020/10/2 11:40
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import scrapy
from practice.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response, **kwargs):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
next_page = response.css('.pager .next a::attr("href")').extract_first()
next_url = response.urljoin(next_page)
yield scrapy.Request(url=next_url, callback=self.parse)运行 接下来,进入目录,运行如下命令:
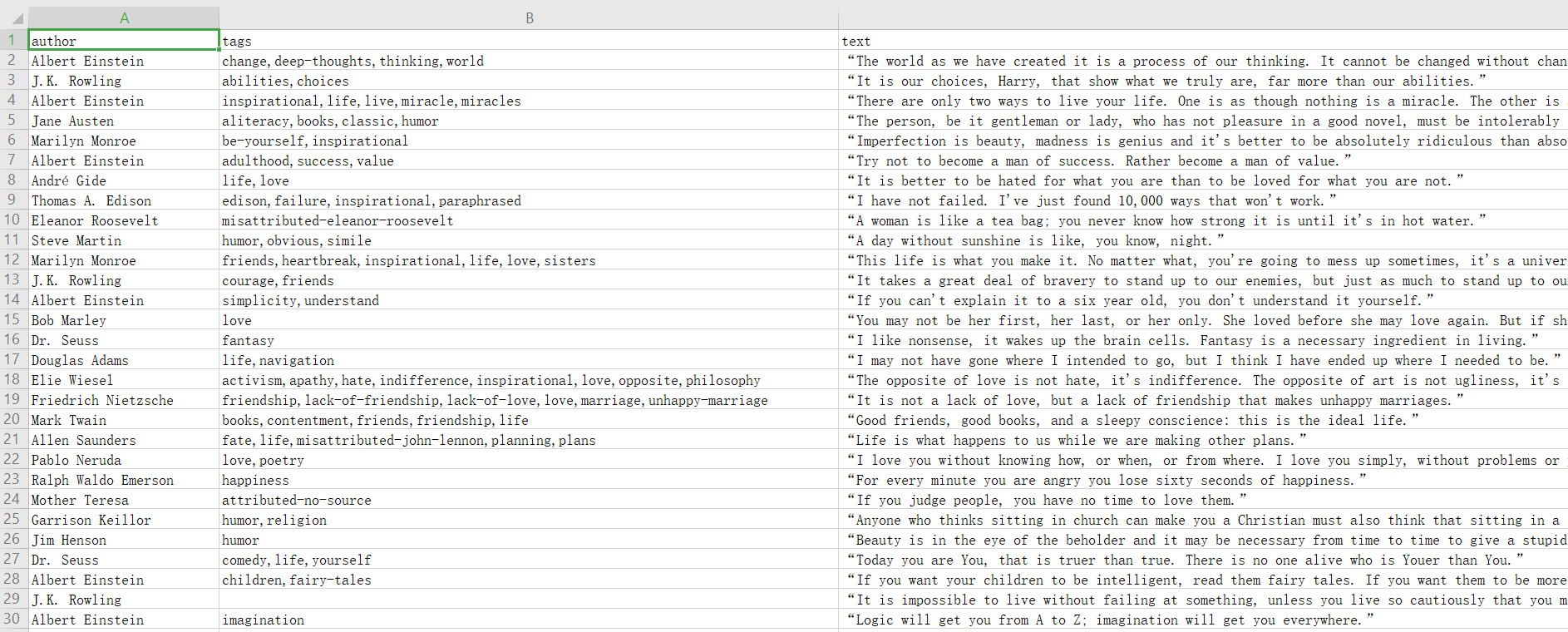
scrapy crawl quotes -o quotes.csv
命令运行后,项目内多了一个 quotes.csv 文件,文件包含了刚才抓取的所有内容。
输出格式还支持很多种,例如 json、xml、pickle、marshal 等,还支持 ftp、s3 等远程输出,另外还可以通过自定义 ItemExporter 来实现其他的输出。
scrapy crawl quotes -o quotes.json
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv其中,ftp 输出需要正确配置用户名、密码、地址、输出路径,否则会报错。
通过 scrapy 提供的 Feed Exports,我们可以轻松地输出抓取结果到文件,对于一些小型项目来说,这应该足够了。不过如果想要更复杂的输出,如输出到数据库等,可以灵活使用 Item Pileline 来完成。
实例2:爬取图片
目标URL:http://sc.chinaz.com/tupian/dangaotupian.html
创建项目
scrapy startproject get_img
cd get_img
scrapy genspider img_spider sc.chinaz.com构造请求
img_spider.py 中定义 start_requests() 方法,比如爬取这个网站里的蛋糕图片,爬取页数为 10,生成 10 次请求,如下所示:
def start_requests(self):
for i in range(1, 11):
if i == 1:
url = 'http://sc.chinaz.com/tupian/dangaotupian.html'
else:
url = f'http://sc.chinaz.com/tupian/dangaotupian_{i}.html'
yield scrapy.Request(url, self.parse)编写 items.py
import scrapy
class GetImgItem(scrapy.Item):
img_url = scrapy.Field()
img_name = scrapy.Field()编写 img_spider.py Spider 类定义了如何爬取某个(或某些)网站,包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(抓取item)
"""
@Author :叶庭云
@Date :2020/10/2 11:40
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import scrapy
from get_img.items import GetImgItem
class ImgSpiderSpider(scrapy.Spider):
name = 'img_spider'
def start_requests(self):
for i in range(1, 11):
if i == 1:
url = 'http://sc.chinaz.com/tupian/dangaotupian.html'
else:
url = f'http://sc.chinaz.com/tupian/dangaotupian_{i}.html'
yield scrapy.Request(url, self.parse)
def parse(self, response, **kwargs):
src_list = response.xpath('//div[@id="container"]/div/div/a/img/@src2').extract()
alt_list = response.xpath('//div[@id="container"]/div/div/a/img/@alt').extract()
for alt, src in zip(alt_list, src_list):
item = GetImgItem() # 生成item对象
# 赋值
item['img_url'] = src
item['img_name'] = alt
yield item编写管道文件 pipelines.py
Scrapy 提供了专门处理下载的 Pipeline,包括文件下载和图片下载。下载文件和图片的原理与抓取页面的原理一样,因此下载过程支持异步和多线程,十分高效。
from scrapy.pipelines.images import ImagesPipeline # scrapy图片下载器
from scrapy import Request
from scrapy.exceptions import DropItem
class GetImgPipeline(ImagesPipeline):
# 请求下载图片
def get_media_requests(self, item, info):
yield Request(item['img_url'], meta={'name': item['img_name']})
def item_completed(self, results, item, info):
# 分析下载结果并剔除下载失败的图片
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
return item
# 重写file_path方法,将图片以原来的名称和格式进行保存
def file_path(self, request, response=None, info=None):
name = request.meta['name'] # 接收上面meta传递过来的图片名称
file_name = name + '.jpg' # 添加图片后缀名
return file_name在这里实现了 GetImagPipeline,继承 Scrapy 内置的 ImagesPipeline,重写了下面几个方法:
- get_media_requests()。它的第一个参数 item 是爬取生成的 Item 对象。我们将它的 url 字段取出来,然后直接生成 Request 对象。此 Request 加入调度队列,等待被调度,执行下载。
- item_completed(),它是当单个 Item 完成下载时的处理方法。因为可能有个别图片未成功下载,所以需要分析下载结果并剔除下载失败的图片。该方法的第一个参数 results 就是该 Item 对应的下载结果,它是一个列表形式,列表每一个元素是一个元组,其中包含了下载成功或失败的信息。这里我们遍历下载结果找出所有成功的下载列表。如果列表为空,那么说明该 Item 对应的图片下载失败了,随即抛出异常DropItem,该 Item 忽略。否则返回该 Item,说明此 Item 有效。
- file_path(),它的第一个参数 request 就是当前下载对应的 Request 对象。这个方法用来返回保存的文件名,接收上面meta传递过来的图片名称,将图片以原来的名称和定义格式进行保存。
配置文件 settings.py
# setting.py
BOT_NAME = 'get_img'
SPIDER_MODULES = ['get_img.spiders']
NEWSPIDER_MODULE = 'get_img.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.25
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'get_img.pipelines.GetImgPipeline': 300,
}
IMAGES_STORE = './images' # 设置保存图片的路径 会自动创建运行程序:
# 切换路径到img_spider的目录
scrapy crawl img_spiderscrapy框架爬虫一边爬取一边下载,下载速度非常快。
查看本地 images 文件夹,发现图片都已经成功下载,如图所示:
到现在为止我们就大体知道了 Scrapy 的基本架构并实操创建了一个 Scrapy 项目,编写代码进行了实例抓取,熟悉了 scrapy 爬虫框架的基本使用。之后还需要更加详细地了解和学习 scrapy 的用法,感受它的强大。
作者:叶庭云
原文链接:https://yetingyun.blog.csdn.net/article/details/108217479



