概述
DOM (Document objectModal) :文档对象模型。
DOM:是浏览器提供的(浏览器特有),专门用来操作网页内容的一些JS对象。
目的:让我们可以使用 Js/TS 代码来操作页面(HTML) 内容,让页面“动”起来,从而实现 Web 开发。
HTML:超文本标记语言,用来创建网页结构。
两者的关系:浏览器根据 HTML 内容创建相应的 DOM 对象,也就是:每个 HTML 标签都有对应的 DOM 对象
获取元素
常用方法有两个:
querySelector (selector)作用:获取某一个DOM元素。
queryseletor (selectocu)作用:同时获取多个D0M元素。
获取一个DOM元素:
document. querySelector (selector) document 对象:文档对象(整个页面),是操作页面内容的入口对象。 selector 参数:是一个 css 选择器(标签、类、id 选择器等)。 作用:查询(获取)与选择器参数匹配的 DOM 元素,但是,只能获取到第一个 推荐使用id选择器,例如
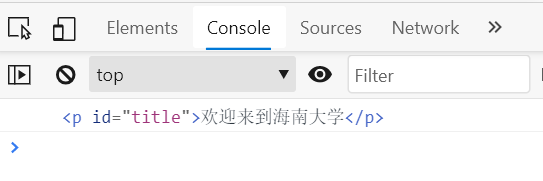
获取html中id为title的标签内容并在控制台输出:
let title = document.querySelector('#title')
console.log(title)
结果如下
调用 querySelector ()通过id选择器获取 DOM 元素时,拿到的元素类型都是 Element. 因为无法根据id来确定元素的类型,所以,该方法就返回了一个宽泛的类型:元素(Element) 类型。 不管是 h1 还是 img 都是元素。 导致新问题:无法访问 img 元素的 src 属性了。 因为: Element 类型只包含所有元素共有的属性和方法(比如: id 属性)。
解决方式:使用类型断言,来手动指定更加具体的类型(比如,此处应该比 Element 类型更加具体)。 比如: 解释:我们确定 id=" image"的元素是图片元素,所以,我们将类型指定为 HTML ImageElement。
let img1 = document.querySelector('#img1') as HTMLImageElement
img1.src = './img/4.jpg'
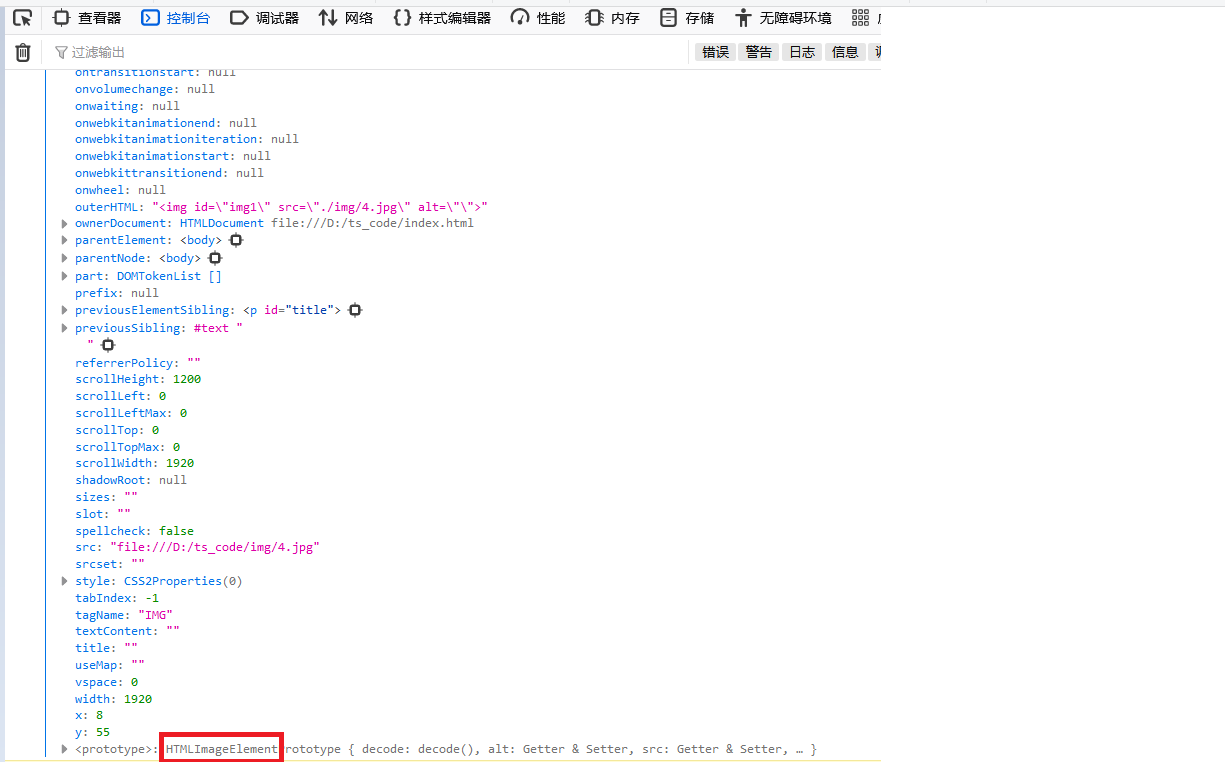
如何知道元素的属性?
技巧:通过 console.dir()打印 DOM 元素,在属性的最后面,即可看到该元素的类型。
let img1 = document.querySelector('#img1') as HTMLImageElement
img1.src = './img/4.jpg'
console.dir(img1)
获取多个 DOM元素:
document . querySelectorAll (selector) 作用:获取所有与选择器参数匹配的 DOM 元素,返回值是一个列表。 推荐:使用 class 选择器。 示例: let、list = document . querySelectorAll(’.a’) 解释:获取页面中所有 class 属性包含 a 的元素。
html中的内容如下
<p id='title'>欢迎来到海南大学</p>
<p class = ' a'>2020年时多灾多难的一年</p>
<p class="b a">2021年将牛气冲天</p>
<img id = 'img1'src="./img/1.jpg" alt="">
<script src = './index.js'></script>
ts 中的内容如下
let list = document.querySelectorAll('.a')
console.log(list)
运行结果如下

操作文本内容
读取: dom. innerText 设置: dom. innerText = ’ 等你下课’ 注意:需要通过类型断言来指定 DOM 元素的具体类型,才可以使用innerText 属性。 例如
let title = document.querySelector('#title') as HTMLParagraphElement
console.log(title.innerHTML)
追加内容如下操作
let title = document.querySelector('#title') as HTMLParagraphElement
title.innerHTML = title.innerHTML + ' 阳光沙滩美女'
console.log(title.innerHTML)
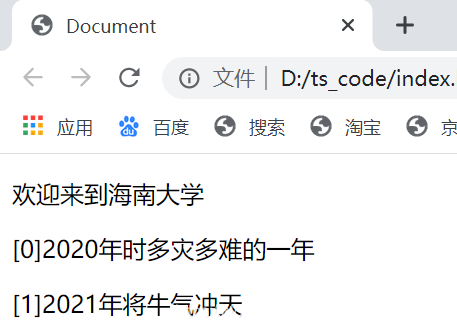
给所有p标签的内容加上索引
let list = document.querySelectorAll('.a')
list.forEach(function (item,index) {
let p = item as HTMLParagraphElement
p.innerHTML = '['+index+']'+p.innerHTML
})
输出结果如下: