

MySQL是一种常用的关系型数据库管理系统,而回表(Index Lookups)是MySQL查询优化中的关键概念之一。本文将对MySQL回表进行详细解析,包括回表的定义、原因、影响因素以及优化策略,帮助读者更好地理解和应用回表技术,提升MySQL查询性能。
回表的定义
回表,顾名思义就是回到表中,也就是先通过普通索引扫描出数据所在的行,再通过行主键ID 取出索引中未包含的数据。所以回表的产生也是需要一定条件的,如果一次索引查询就能获得所有的select 记录就不需要回表,如果select 所需获得列中有其他的非索引列,就会发生回表动作。即基于非主键索引的查询需要多扫描一棵索引树。
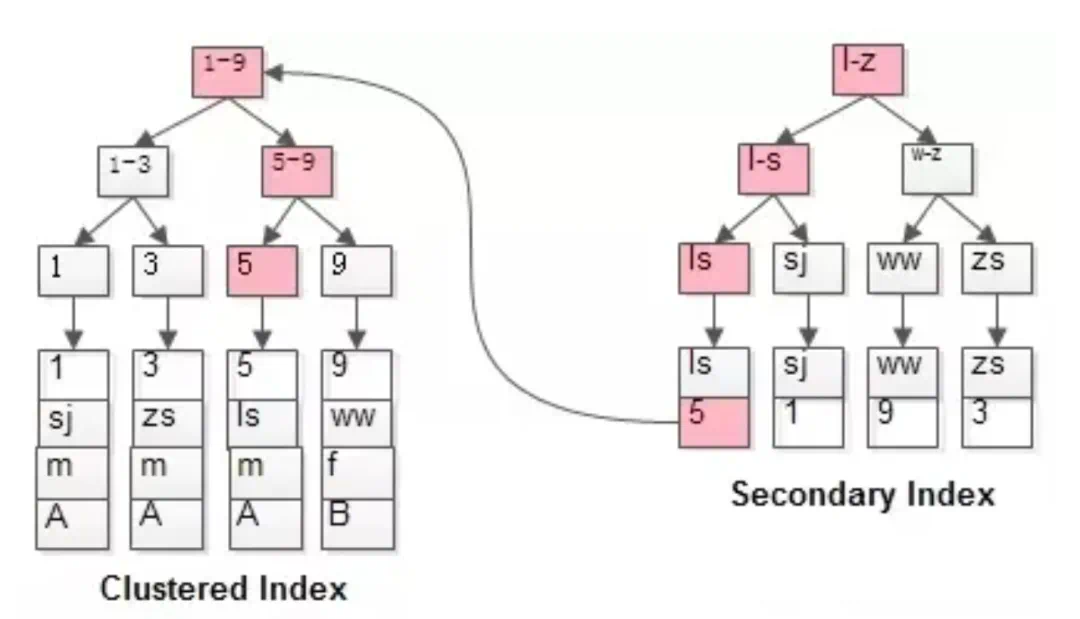
回表的原因
- 列不在索引中:当查询所需的列不在创建的索引中时,MySQL无法直接从索引中获取完整的结果,而需要回到数据表中查找缺失的数据。
- 覆盖索引不完全:有时,索引可以覆盖查询所需的列,但由于索引中包含的列不足以满足查询的全部需求,仍然需要回表操作。
回表对查询性能的影响
- 增加IO开销:回表操作需要额外的磁盘读取操作,增加了数据库的负载和查询时间。
- 可能导致缓存失效:回表操作可能导致数据库缓存(如InnoDB的缓冲池)的失效,降低了查询性能。
- 延长查询时间:回表操作需要额外的访问和处理时间,对查询的响应时间产生负面影响。
优化策略和示例代码
创建覆盖索引
覆盖索引是一种包含查询所需的全部列的索引,可以避免回表操作。下面是创建覆盖索引的示例代码:
CREATE INDEX idx_users_covering ON users (id, name, email);通过创建索引"idx_users_covering",包含了id、name和email列,MySQL可以直接从索引中获取查询所需的全部列,无需回表操作。
优化查询语句
优化查询语句可以减少回表操作的发生。确保只使用覆盖索引的列,避免不必要的回表操作。下面是一个示例查询语句:
SELECT id, name, email
FROM users
WHERE id = 1;在查询语句中,我们只选择了需要的列(id、name和email),避免获取不必要的数据。
通过合理的索引设计和优化查询语句,可以减少回表操作,提高查询性能和响应速度。
总结
MySQL回表是影响查询性能的重要因素。了解回表的定义、原因和影响因素,以及应用合适的优化策略,可以帮助开发者更好地设计和优化数据库查询,提升系统的整体性能和响应速度。通过示例代码的演示,读者可以更直观地理解回表技术的应用。在实际的MySQL应用中,合理设计索引、优化查询语句和定期性能优化都是减少回表操作、提升查询性能的关键步骤。

如果你对编程知识和相关职业感兴趣,欢迎访问编程狮官网(https://www.w3cschool.cn/)。在编程狮,我们提供广泛的技术教程、文章和资源,帮助你在技术领域不断成长。无论你是刚刚起步还是已经拥有多年经验,我们都有适合你的内容,助你取得成功。



