

在互联网,唯一ID的生成是一项关键任务,用于标识和区分各种实体,如用户、订单、产品等。本文将详细介绍互联网常用的唯一ID生成方式,包括自增ID、UUID、雪花算法等,并探讨它们的特点和适用场景。
自增ID
自增ID是一种简单而常见的唯一ID生成方式,通过数据库的自增字段实现。每次插入新记录时,自动递增生成唯一ID。这种方式简单高效,适用于单体应用或小规模系统。示例代码(使用MySQL):
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
);
INSERT INTO users (name) VALUES ('John');
INSERT INTO users (name) VALUES ('Jane');自增ID的优点是易于实施和管理,但在分布式系统或多个数据库实例中可能存在冲突的风险。
UUID
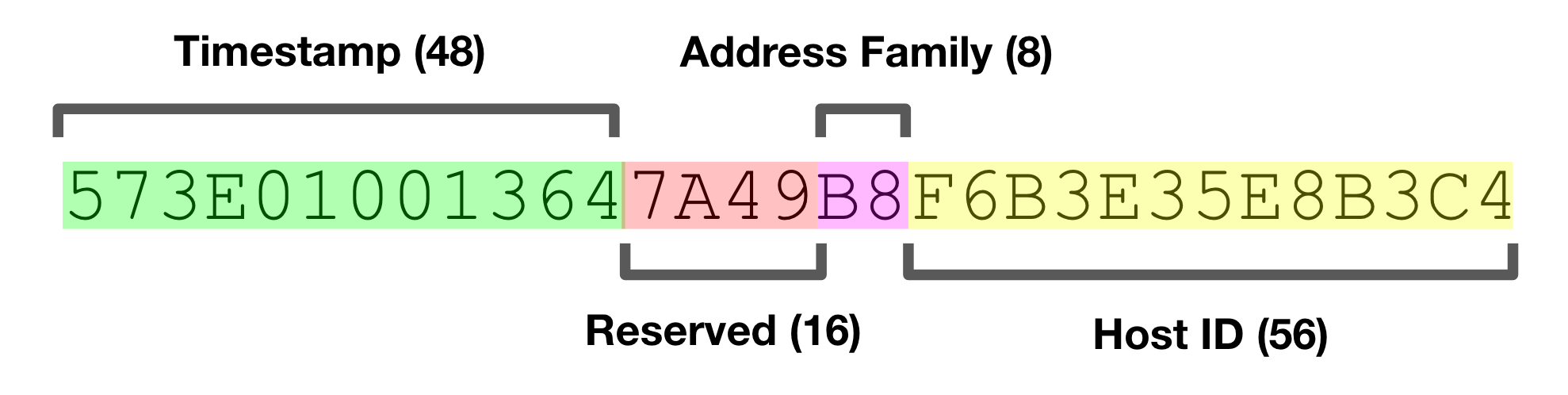
UUID(Universally Unique Identifier)是一种标准化的唯一ID生成方式,通过算法生成128位的字符串。UUID保证了在全球范围内的唯一性,不依赖于中央控制机构。
在Python中,可以使用uuid库生成UUID。示例代码:
import uuid
uid = uuid.uuid4()
print(uid)UUID的优点是全局唯一,无需依赖数据库自增或其他机制,适用于分布式系统。然而,UUID的字符串较长,不适合作为数据库索引或URL中的参数。
雪花算法
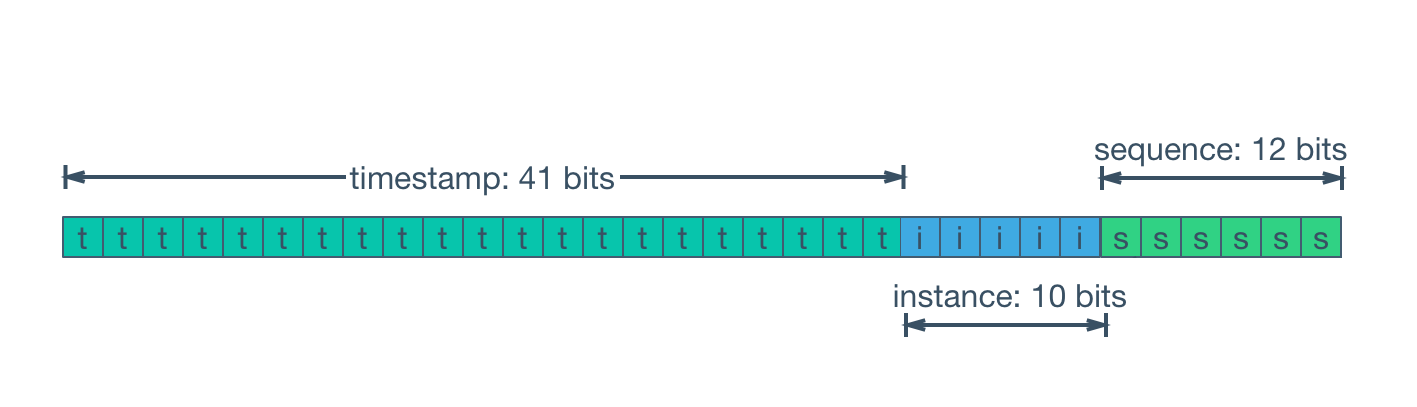
雪花算法(Snowflake)是Twitter开源的一种分布式唯一ID生成算法。它将唯一ID分为不同的部分,包括时间戳、机器ID和序列号。这些部分的组合保证了生成的唯一ID在分布式系统中的唯一性和有序性。
示例代码(使用Python实现):
import time
class Snowflake:
def __init__(self, worker_id):
self.worker_id = worker_id
self.sequence = 0
self.last_timestamp = -1
def generate_id(self):
timestamp = int(time.time() * 1000)
if timestamp < self.last_timestamp:
raise Exception("Clock moved backwards!")
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & 4095
if self.sequence == 0:
timestamp = self.wait_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
# 生成ID
unique_id = ((timestamp - 1420041600000) << 22) | (self.worker_id << 12) | self.sequence
return unique_id
def wait_next_millis(self, last_timestamp):
timestamp = int(time.time() * 1000)
while timestamp <= last_timestamp:
timestamp = int(time.time() * 1000)
return timestamp
# 使用示例
snowflake = Snowflake(worker_id=1)
unique_id = snowflake.generate_id()
print(unique_id)雪花算法的优点是在分布式系统中生成唯一ID,且具有有序性。它的缺点是依赖于系统时钟的准确性,同时需要分配和管理机器ID。
总结
唯一ID的生成方式多种多样,每种方式都有自己的特点和适用场景。自增ID适用于单体应用或小规模系统,UUID适用于分布式系统,而雪花算法适用于需要分布式、有序、高性能的场景。开发者可以根据实际需求选择合适的唯一ID生成方式,确保在互联网应用中实现唯一性标识和数据完整性。



