

在神经网络的推理过程中,如果全都默认使用相同的一个比较高的数据精度的话,对于计算机硬件的显存具有一定的要求,运算量也会增大,对应的运算时间就会降低,宏观的讲就是运算速度变慢了。但实际上,针对不同的层我们可以采用不同的数据精度进行计算以达到节省内存和加快速度的目的。这种方法叫做自动混合精度(amp),那么pytorch怎么使用amp呢?接下来我们就来介绍一下pytorch怎么进行混合精度训练吧。
简介
AMP:Automatic mixed precision,自动混合精度,可以在神经网络推理过程中,针对不同的层,采用不同的数据精度进行计算,从而实现节省显存和加快速度的目的。
在Pytorch 1.5版本及以前,通过NVIDIA提供的apex库可以实现amp功能。但是在使用过程中会伴随着一些版本兼容和奇怪的报错问题。
从1.6版本开始,Pytorch原生支持自动混合精度训练,并已进入稳定阶段,AMP 训练能在 Tensor Core GPU 上实现更高的性能并节省多达 50% 的内存。
环境
Python 3.8
Pytorch 1.7.1
CUDA 11 + cudnn 8
NVIDIA GeFore RTX 3070
ps:后续使用移动端的3070,或者3080结合我目前训练的分类网络来测试实际效果
原理
关于低精度计算
当前的深度学习框架大都采用的都是FP32来进行权重参数的存储,比如Python float的类型为双精度浮点数 FP64,PyTorch Tensor的默认类型为单精度浮点数FP32。
随着模型越来越大,加速训练模型的需求就产生了。在深度学习模型中使用FP32主要存在几个问题,第一模型尺寸大,训练的时候对显卡的显存要求高;第二模型训练速度慢;第三模型推理速度慢。
其解决方案就是使用低精度计算对模型进行优化。
推理过程中的模型优化目前比较成熟的方案就是FP16量化和INT8量化,NVIDIA TensorRT等框架就可以支持,这里不再赘述。训练方面的方案就是混合精度训练,它的基本思想很简单: 精度减半(FP32→ FP16) ,训练时间减半。
与单精度浮点数float32(32bit,4个字节)相比,半精度浮点数float16仅有16bit,2个字节组成。
可以很明显的看到,使用FP16可以解决或者缓解上面FP32的两个问题:显存占用更少:通用的模型FP16占用的内存只需原来的一半,训练的时候可以使用更大的batchsize。
计算速度更快:有论文指出半精度的计算吞吐量可以是单精度的 2-8 倍。
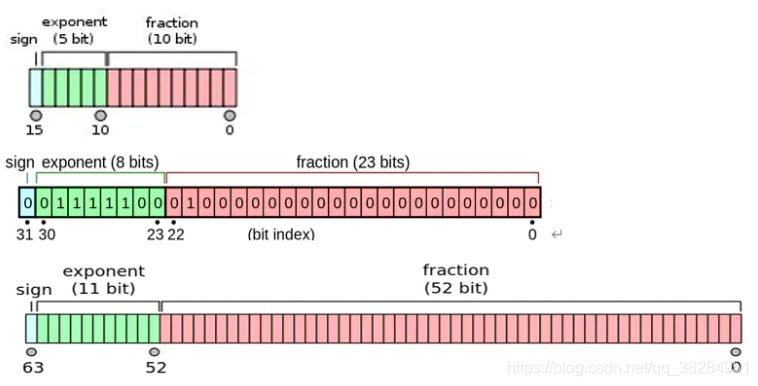
从上到下依次为 fp16、fp32 、fp64
当前很多NVIDIA GPU搭载了专门为快速FP16矩阵运算设计的特殊用途Tensor Core,比如Tesla P100,Tesla V100、Tesla A100、GTX 20XX 和RTX 30XX等。
Tensor Core是一种矩阵乘累加的计算单元,每个Tensor Core每个时钟执行64个浮点混合精度操作(FP16矩阵相乘和FP32累加),英伟达宣称使用Tensor Core进行矩阵运算可以轻易的提速,同时降低一半的显存访问和存储。
随着Tensor Core的普及FP16计算也一步步走向成熟,低精度计算也是未来深度学习的一个重要趋势。
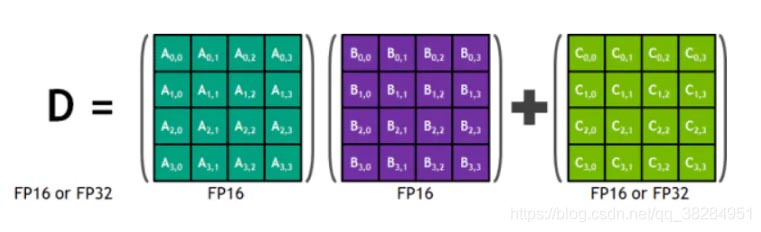
Tensor Core 的 4x4x4 矩阵乘法与累加
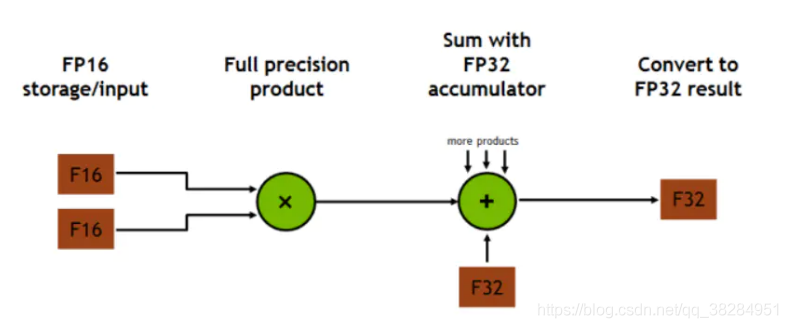
Volta GV100 Tensor Core 流程图
自动混合精度训练
不同于在推理过程中直接削减权重精度,在模型训练的过程中,直接使用半精度进行计算会导致的两个问题的处理:舍入误差(Rounding Error)和溢出错误(Grad Overflow / Underflow)。
舍入误差: float16的最大舍入误差约为 (~2 ^-10 ),比float32的最大舍入误差(~2 ^-23) 要大不少。 对足够小的浮点数执行的任何操作都会将该值四舍五入到零,在反向传播中很多甚至大多数梯度更新值都非常小,但不为零。 在反向传播中舍入误差累积可以把这些数字变成0或者 nan, 这会导致不准确的梯度更新,影响网络的收敛。
溢出错误: 由于float16的有效的动态范围约为 ( 5.96×10^-8 ~ 6.55×10^4),比单精度的float32(1.4x10^-45 ~ 1.7x10^38)要狭窄很多,精度下降(小数点后16相比较小数点后8位要精确的多)会导致得到的值大于或者小于fp16的有效动态范围,也就是上溢出或者下溢出。
在深度学习中,由于激活函数的的梯度往往要比权重梯度小,更易出现下溢出的情况。2018年ICLR论文 Mixed Precision Training 中提到,简单的在每个地方使用FP16会损失掉梯度更新小于2^-24的值——大约占他们的示例网络所有梯度更新的5%。
解决方案就是使用混合精度训练(Mixed Precision)和损失缩放(Loss Scaling):
1、混合精度训练:
混合精度训练是一种通过在FP16上执行尽可能多的操作来大幅度减少神经网络训练时间的技术,在像线性层或是卷积操作上,FP16运算较快,但像Reduction运算又需要 FP32的动态范围。通过混合精度训练的方式,便可以在部分运算操作使用FP16,另一部分则使用 FP32,混合精度功能会尝试为每个运算使用相匹配的数据类型,在内存中用FP16做储存和乘法从而加速计算,用FP32做累加避免舍入误差。这样在权重更新的时候就不会出现舍入误差导致更新失败,混合精度训练的策略有效地缓解了舍入误差的问题。
2、损失缩放:
即使用了混合精度训练,还是会存在无法收敛的情况,原因是激活梯度的值太小,造成了下溢出。损失缩放是指在执行反向传播之前,将损失函数的输出乘以某个标量数(论文建议从8开始)。 乘性增加的损失值产生乘性增加的梯度更新值,提升许多梯度更新值到超过FP16的安全阈值2^-24。 只要确保在应用梯度更新之前撤消缩放,并且不要选择一个太大的缩放以至于产生inf权重更新(上溢出) ,从而导致网络向相反的方向发散。
使用Pytorch AMP
Pytorch原生的amp模式使用起来相当简单,只需要从torch.cuda.amp导入GradScaler和 autocast这两个函数即可。torch.cuda.amp的名字意味着这个功能只能在cuda上使用,事实上,这个功能正是NVIDIA的开发人员贡献到PyTorch项目中的。
Pytorch在amp模式下维护两个权重矩阵的副本,一个主副本用 FP32,一个半精度副本用 FP16。 梯度更新使用FP16矩阵计算,但更新于 FP32矩阵。 这使得应用梯度更新更加安全。
autocast上下文管理器实现了 FP32到FP16的转换,它会自动判别哪些层可以进行FP16哪些层不可以。 GradScaler对梯度更新计算(检查是否溢出)和优化器(将丢弃的batches转换为 no-op)进行控制,通过放大loss的值来防止梯度的溢出。
在训练中的具体使用方法如下所示:
def train():
batch_size = 8
epochs = 10
lr = 1e-3
size = 256
num_class = 35
use_amp = True
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('torch version: {}'.format(torch.__version__))
print('amp: {}'.format(use_amp))
print('device: {}'.format(device))
print('epochs: {}'.format(epochs))
print('learn rate: {}'.format(lr))
print('batch size: {}'.format(batch_size))
net = ERFNet(num_classes=num_class).to(device)
train_data = CityScapesDataset('D:\dataset\cityscapes',
'D:\dataset\cityscapes\trainImages.txt',
'D:\dataset\cityscapes\trainLabels.txt',
size, num_class)
val_data = CityScapesDataset('D:\dataset\cityscapes',
'D:\dataset\cityscapes\valImages.txt',
'D:\dataset\cityscapes\valLabels.txt',
size, num_class)
train_dataloader = DataLoader(train_data, batch_size=batch_size, shuffle=False, num_workers=8)
val_dataloader = DataLoader(val_data, batch_size=batch_size, shuffle=False, num_workers=4)
opt = torch.optim.Adam(net.parameters(), lr=lr)
criterion = torch.nn.CrossEntropyLoss(ignore_index=255)
if use_amp:
scaler = torch.cuda.amp.GradScaler()
writer = SummaryWriter("summary")
train_loss = AverageMeter()
val_acc = AverageMeter()
val_miou = AverageMeter()
for epoch in range(0, epochs):
train_loss.reset()
val_acc.reset()
val_miou.reset()
with tqdm(total=train_data.__len__(), unit='img', desc="Epoch {}/{}".format(epoch + 1, epochs)) as pbar:
# train
net.train()
for img, mask in train_dataloader:
img = img.to(device)
mask = mask.to(device)
n = img.size()[0]
opt.zero_grad()
if use_amp:
with torch.cuda.amp.autocast():
output = net(img)
loss = criterion(output, mask)
scaler.scale(loss).backward()
scaler.step(opt)
scaler.update()
else:
output = net(img)
loss = criterion(output, mask)
loss.backward()
opt.step()
train_loss.update(loss.item(), n)
pbar.set_postfix(**{"loss": train_loss.avg})
pbar.update(img.size()[0])
writer.add_scalar('train_loss', train_loss.avg, epoch)
# eval
net.eval()
for img, mask in val_dataloader:
img = img.to(device)
mask = mask
n = img.size()[0]
output = net(img)
pred_mask = torch.softmax(output, dim=1)
pred_mask = pred_mask.detach().cpu().numpy()
pred_mask = np.argmax(pred_mask, axis=1)
true_mask = mask.numpy()
acc, acc_cls, mean_iu, fwavacc = evaluate(pred_mask, true_mask, num_class)
val_acc.update(acc)
val_miou.update(mean_iu)
writer.add_scalar('val_acc', val_acc.avg, epoch)
writer.add_scalar('val_miou', val_miou.avg, epoch)
pbar.set_postfix(**{"loss": train_loss.avg, "val_acc": val_acc.avg, "val_miou": val_miou.avg})实验
硬件使用NVIDIA Geforce RTX 3070作为测试卡,这块卡有184个Tensor Core,能比较好的支持amp模式。
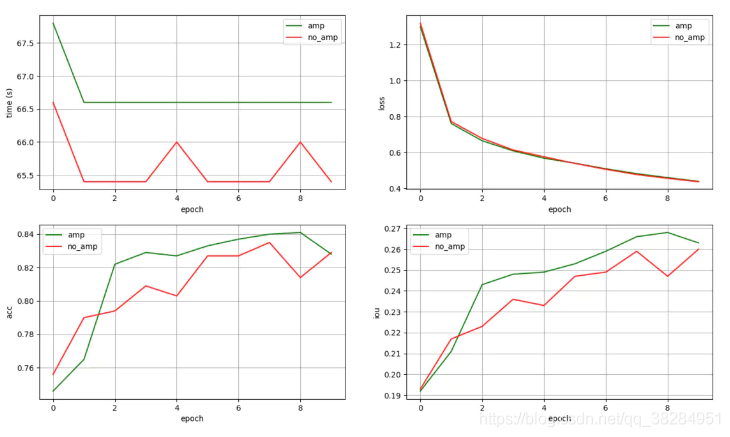
模型使用ERFNet分割模型作为基准,cityscapes作为测试数据,10个epoch下的测试效果如下所示:
在模型的训练性能方面,amp模式下的平均训练时间并没有明显节省,甚至还略低于正常模式。
显存的占用大约节省了25%,对于需要大量显存的模型来说这个提升还是相当可观的。
理论上训练速度应该也是有提升的,到Pytorch的GitHub issue里翻了一下,好像30系显卡会存在速度提不上来的问题,不太清楚是驱动支持不到位还是软件适配不到位。
| Metrics | time | memory |
|---|---|---|
| AMP | 66.72s | 2.5G |
| NO_AMP | 65.64s | 3.3G |
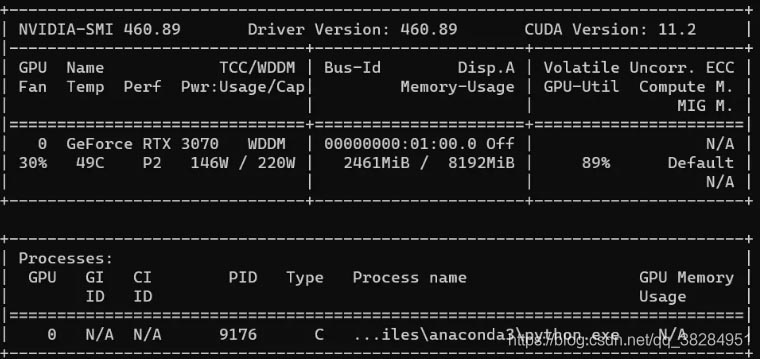
amp
no_amp
在模型的精度方面,在不进行数据shuffle的情况下统计了10个epoch下两种模式的train_loss和val_acc,可以看出不管是训练还是推理,amp模式并没有带来明显的精度损失。
cmp
小结
到此这篇关于pytorch怎么进行混合精度训练的文章就介绍到这了,更多pytorch相关学习教程请搜索W3Cschool以前的文章或继续浏览下面的相关文章。希望大家以后多多支持W3Cschool!



