

关键的 PostgreSQL 客户端包含有价值的数据,应定期备份 PostgreSQL 数据库。它的过程非常简单,重要的是要清楚地了解技术和假设。
SQL 转储
这种转储方法背后的想法是使用 SQL 命令从 DataCenter1 生成一个文本文件,当反馈到 DataCenter2 服务器时,将重新创建与转储时相同状态的数据库。在这种情况下,如果客户端无法访问主服务器,他们可以访问 BCP 服务器。PostgreSQL 为此提供了实用程序 pg_dump。该命令的基本用法是: pg_dump dbname >backupoutputfile.db。
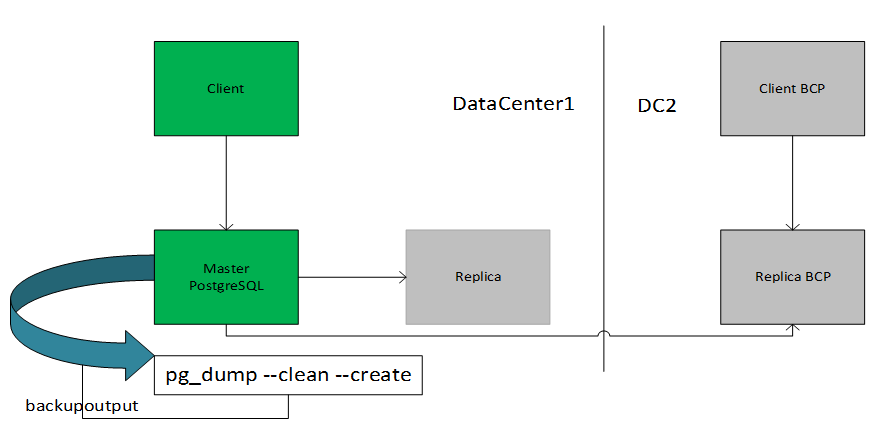
如您所见,pg_dump 将其结果写入标准输出。下面,我们将看到这如何有用。
pg_dump 是一个常规的 PostgreSQL 客户端应用程序。这意味着您可以从任何有权访问数据库的远程主机执行此备份过程。pg_dump 不以特殊权限运行。特别是,它必须对您要备份的所有表具有读访问权限,因此在实践中,您几乎总是必须以数据库超级用户身份运行它。
pg_dump 创建的转储在内部是一致的,也就是说,转储代表 pg_dump 开始运行时数据库的快照。pg_dump 在工作时不会阻止对数据库的其他操作。(具有排他锁的例外,例如大多数形式的 ALTER TABLE。)
重要提示:如果您的数据库模式依赖于 OID(例如作为外键),您必须指示 pg_dump 也转储 OID。为此,请使用 -o 命令行选项。
SQL 转储自动化
- 首先,创建剧本 pgbackup.yml
- 创建角色 pgbackup,它将从 pgbackup.yml 中调用
Pgbackup.yml
---
- hosts: database_prim:database_replica
gather_facts: true
vars_files:
- mysecret_vars/{{ environ }}.yml
# This is to Identify if DB is Primary and replicating data to secondary
tasks:
- name: select pg status
command: psql -c "SELECT pg_is_in_recovery();"
register: IsPromoted
changed_when: False
environment:
PGDATABASE: "{{ pg_database }}"
PGUSER : "{{ pg_username }}"
PGPASSWORD : "{{ pg_password }}"
#Get the DB parameter from run time on Client application, Not required if you have parameters
- block:
- name: Get client database settings
shell: "awx-manage print_settings | grep '^DATABASES'"
register: results
changed_when: False
delegate_to: "{{ groups['client’][0] }}"
- name: Ingest client database settings
set_fact:
client_db_settings: "{{ results.stdout | regex_replace('DATABASES\\s+= ', '') }}"
delegate_to: "{{ groups['client'][0] }}"
- include_role:
name: pgbackup
when: "'f' in IsPromoted.stdout"
tags: pgbackup- pgbackup 角色
---
- name: Determine the timestamp for the backup.
set_fact:
now: '{{ lookup("pipe", "date +%F-%T") }}'
- name: Create a directory for a backup to live.
file:
path: '{{ backup_dir.rstrip("/") }}/{{ now }}/'
mode: 0775
owner: root
state: directory
- name: Create a directory for non-instance specific backups
file:
path: '{{ backup_dir.rstrip("/") }}/common/'
mode: 0775
owner: root
state: directory
# create dump, Here adding runtime param. You can add param whatever ways
- name: Perform a PostgreSQL dump.
shell: "pg_dump --clean --create --host='{{ client_db_settings.default.HOST }}' --port={{ client_db_settings.default.PORT }} --username='{{ tower_db_settings.default.USER }}' --dbname='{{ tower_db_settings.default.NAME }}' > pgbackup.db"
args:
chdir: '{{ backup_dir.rstrip("/") }}/common/'
environment:
PGPASSWORD: "{{ client_db_settings.default.PASSWORD }}"
- name: Copy file with owner and permissions
copy:
src: '{{ backup_dir.rstrip("/") }}/common/pgbackup.db'
dest: '{{ backup_dir.rstrip("/") }}/{{ now }}/'
remote_src: yes[all:vars]
# database settings
.linux.us.ams1907.com
[client]
linuxclient.us.com
[database_prim]
linuxmas.us.com
[database_replica]
linuxreplica.us.com
mysecret_vars/{{ environ }}.yml
ansible-vault encrypt mysecretvar.yml存储此类参数:pg_password、pg_username 和 pg_database
恢复转储
pg_dump 创建的文本文件旨在由 psql 程序读取。恢复转储的一般命令形式是 psql dbname < infile
在数据中心 2 中恢复
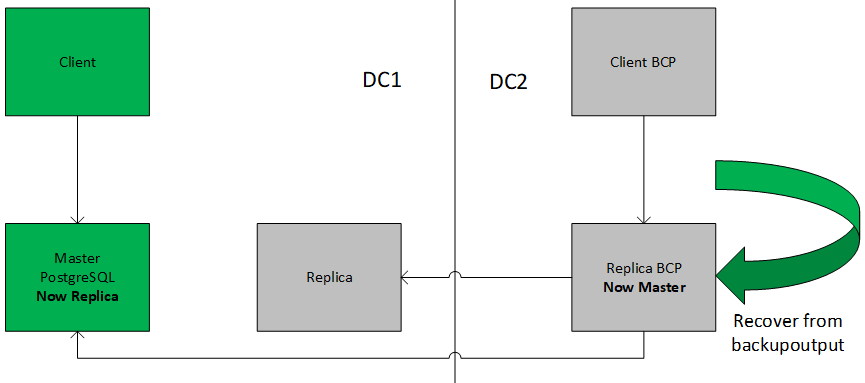
Infile 是您用作 pg_dump 命令的备份输出文件的文件。该命令不会创建数据库 dbname,因此您必须在执行 psql 之前从 template0 自己创建它(例如,使用 createdb -T template0 dbname)。psql 支持类似于 pg_dump 的选项,用于指定要连接的数据库服务器和要使用的用户名。有关更多信息,请参阅 psql 参考页。
在还原 SQL 转储之前,拥有对象或被授予转储数据库中对象权限的所有用户必须已经存在。如果不这样做,则还原将无法重新创建具有原始所有权和/或权限的对象。
无论哪种方式,您都将拥有一个仅部分恢复的数据库。或者,您可以指定整个转储应作为单个事务恢复,以便完全完成或完全回滚恢复。这种模式可以通过将 -1 或 --single-transaction 命令行选项传递给 psql 来指定。使用此模式时,请注意,即使是最小的错误也可能回滚已运行数小时的还原。但是,这可能仍然比在部分还原转储后手动清理复杂数据库更可取。
数据库恢复
- hosts: database_prim[0]
tasks:
- name: Get client database settings
shell: "awx-manage print_settings | grep '^DATABASES'"
register: results
changed_when: False
delegate_to: "{{ groups['client'][0] }}"
- name: Ingest client database settings
set_fact:
tower_db_settings: "{{ results.stdout | regex_replace('DATABASES\\s+= ', '') }}"
delegate_to: "{{ groups['client'][0] }}"
# Create User
- name: PostgreSQL | Create test user if its not there
postgresql_user:
name: "test"
password: "{{ client_db_settings.default.PASSWORD }}"
port: "5432"
state: present
login_user: "postgres"
no_password_changes: no
become: yes
become_user: "postgres"
become_method: su
# Create Database
- name: PostgreSQL | Create test Database if its not there
postgresql_db:
name: "test"
owner: "test"
encoding: "UTF-8"
lc_collate: "en_US.UTF-8"
lc_ctype: "en_US.UTF-8"
port: "5432"
template: "template0"
state: present
login_user: "postgres"
become: yes
become_user: "postgres"
become_method: su
- include_role:
name: pgrecover
---
- name: Create a directory for non-instance specific backups
file:
path: '{{ backup_dir.rstrip("/") }}/restore/'
mode: 0775
owner: root
state: directory
- name: Copy file for restore
copy:
src: '{{ backup_dir.rstrip("/") }}/common/client.db'
dest: '{{ backup_dir.rstrip("/") }}/restore/'
remote_src: yes
- name: Perform a PostgreSQL restore
shell: "psql --host='{{ client_db_settings.default.HOST }}' --port={{ client_db_settings.default.PORT }} --username='{{ client_db_settings.default.USER }}' --dbname='test' < ./client.db"
args:
chdir: '{{ backup_dir.rstrip("/") }}/restore/'
environment:
PGPASSWORD: "{{ client_db_settings.default.PASSWORD }}"使用 pg_dumpall
pg_dump 一次只转储一个数据库,它不会转储有关角色或表空间的信息(因为它们是集群范围的而不是每个数据库的)。为了支持方便地转储数据库集群的全部内容,提供了 pg_dumpall 程序。pg_dumpall 备份给定集群中的每个数据库,还保留集群范围的数据,例如角色和表空间定义。该命令的基本用法是:
pg_dumpall > 输出文件
可以使用 psql 恢复生成的转储: psql -f infile Postgres。
(实际上,您可以指定任何现有的数据库名称作为开始,但是如果您要重新加载到一个空集群中,那么通常应该使用 Postgres。)在恢复 pg_dumpall 转储时始终需要具有数据库超级用户访问权限,因为那是需要恢复角色和表空间信息。如果您使用表空间,请注意转储中的表空间路径是否适合新安装。
pg_dumpall 通过发出命令来重新创建角色、表空间和空数据库,然后为每个数据库调用 pg_dump。这意味着虽然每个数据库将在内部保持一致,但不同数据库的快照可能不会完全同步。
通过在自动化脚本中实现微小的更改,您可以将其更改为 pg_dumpall。



