

数据工程师和分析师对大量数据运行交互式临时分析的需求继续呈爆炸性增长。数据平台团队越来越多地使用联合SQL 查询引擎 PrestoDB 为各种用例运行此类分析,跨越广泛的数据湖和数据库就地,而无需移动数据。PrestoDB 由 Linux 基金会的Presto 基金会托管,是在 Facebook、Uber 和 Twitter 上大规模运行的同一个项目。
让我们来看看 Presto 的一些重要特征,这些特征解释了它的日益普及。
更轻松地与生态系统集成
Presto 旨在与现有数据生态系统无缝集成,无需对正在进行的系统进行任何修改。这就像使用额外的更快的数据访问接口为您现有的堆栈增压。
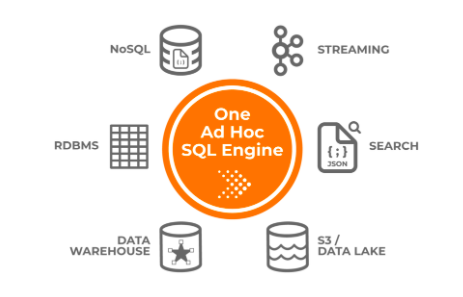
Presto 提供额外的计算层以加快分析速度。它不存储数据,这使它具有能够根据需求向上和向下扩展查询资源的巨大优势。
这种计算和存储分离使 Presto 查询引擎非常适合云环境。大多数云部署利用对象存储,它已经从计算层中分离出来,并自动扩展以优化资源成本。
统一的 SQL 接口
SQL 是迄今为止最古老、使用最广泛的数据分析语言。分析师、数据工程师和数据科学家使用 SQL 来探索数据、构建仪表板并通过 Jupyter 和 Zeppelin 等笔记本或 Tableau、PowerBI 和 Looker 等 BI 工具来测试假设。
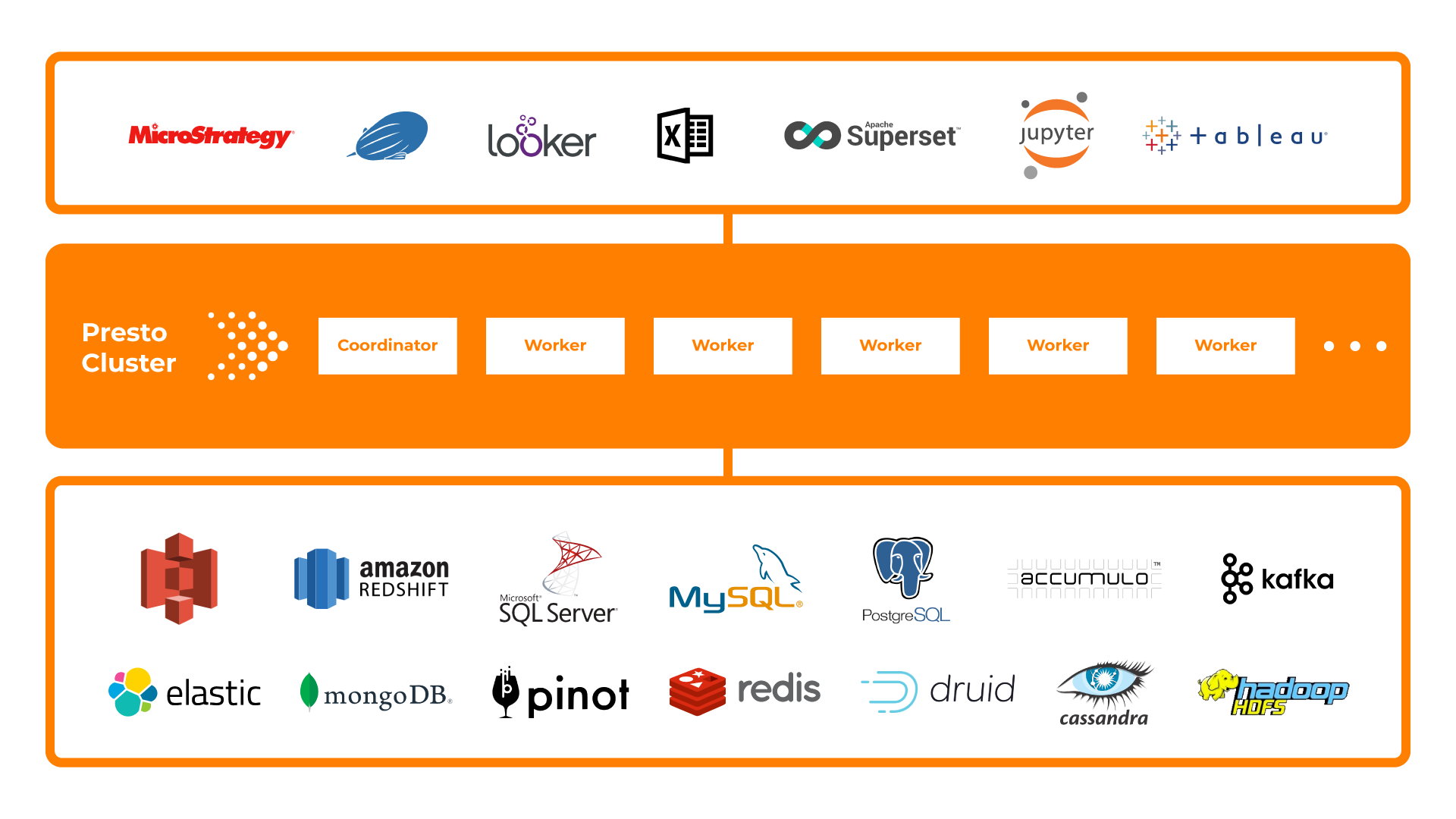
Presto 是一个联合查询引擎,它不仅能够从分布式文件系统中查询数据,还能够从其他来源查询数据,例如 Cassandra、Elasticsearch 和 RDBMS 等 NoSQL 存储,甚至是 Kafka 等消息队列。
表现
Facebook 团队开发 Presto 是因为 Apache Hive 不适合交互式查询。Hive 的下划线架构通过执行多个 MapReduce 和 Tez 作业来执行查询,非常适合大型复杂作业,但不适用于低延迟查询。Hive 项目最近使用 Hive LLAP 引入了内存缓存;然而,它适用于某些类型的查询,但它也使 Hive 更加资源密集。
同样,Apache Spark 非常适合使用内存计算的大型复杂作业。但是,它不如 Presto 交互式 BI 查询有效。
Presto 专为高性能而打造,具有多项关键功能和优化,例如代码生成、内存中处理和流水线执行。Presto 查询在工作节点上共享一个长期存在的 Java 虚拟机 (JVM) 进程,从而避免了产生新 JVM 容器的开销。
查询联合
Presto 提供了一个统一的 SQL 方言,可以抽象出所有支持的数据源。这是一项强大的功能,用户无需了解底层系统的连接和 SQL 方言。
适合云的设计
Presto 将存储和计算分开运行的基本设计使其在云环境中操作极其方便。由于 Presto 集群不存储任何数据,因此可以根据负载自动扩展,而不会造成任何数据丢失。
如您所见,Presto 为交互式即席查询提供了许多优势。难怪数据平台团队越来越多地使用 Presto 作为事实上的 SQL 查询引擎,在不需要移动数据的情况下跨数据源运行分析。



